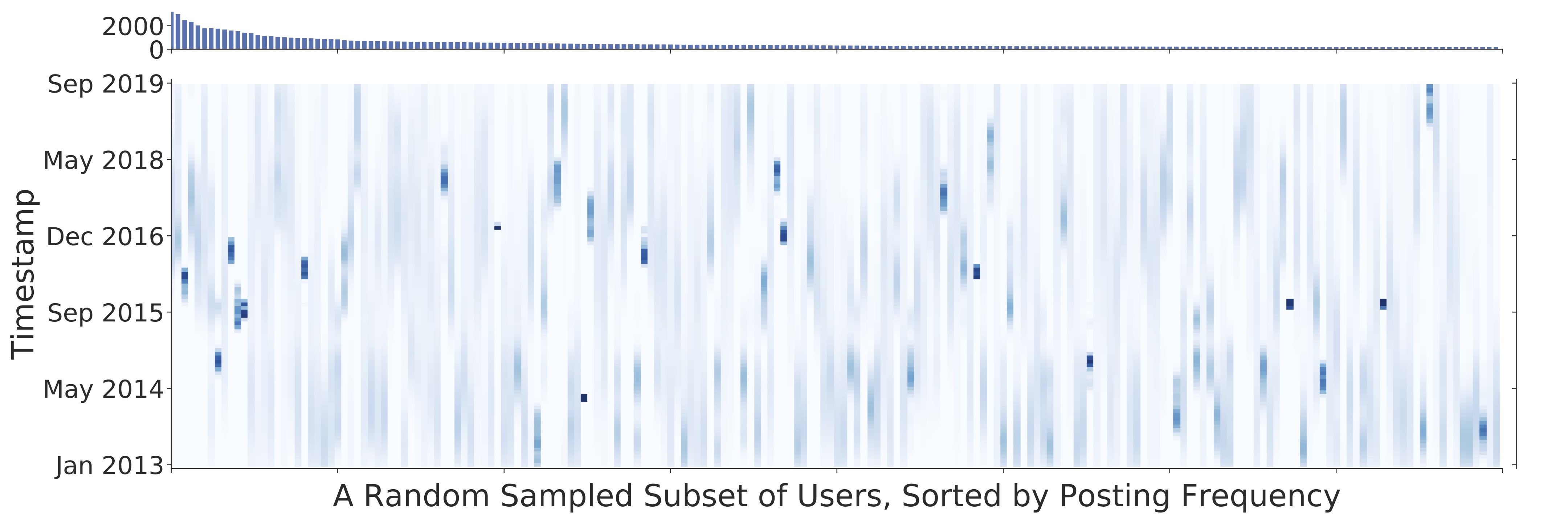
Continual learning systems will interact with humans, with each other, and with the physical world through time — and continue to learn and adapt as they do. An important open problem for continual learning is a large-scale benchmark which enables realistic evaluation of algorithms. In this paper, we study a natural setting for continual learning on a massive scale. We introduce the problem of personalized online language learning (POLL), which involves fitting personalized language models to a population of users that evolves over time. To facilitate research on POLL, we collect massive datasets of Twitter posts. These datasets, Firehose10M and Firehose100M, comprise 100 million tweets, posted by one million users over six years. Enabled by the Firehose datasets, we present a rigorous evaluation of continual learning algorithms on an unprecedented scale. Based on this analysis, we develop a simple algorithm for continual gradient descent (ConGraD) that outperforms prior continual learning methods on the Firehose datasets as well as earlier benchmarks. Collectively, the POLL problem setting, the Firehose datasets, and the ConGraD algorithm enable a complete benchmark for reproducible research on web-scale continual learning.
Drinking from a Firehose: Continual Learning with Web-scale Natural Language