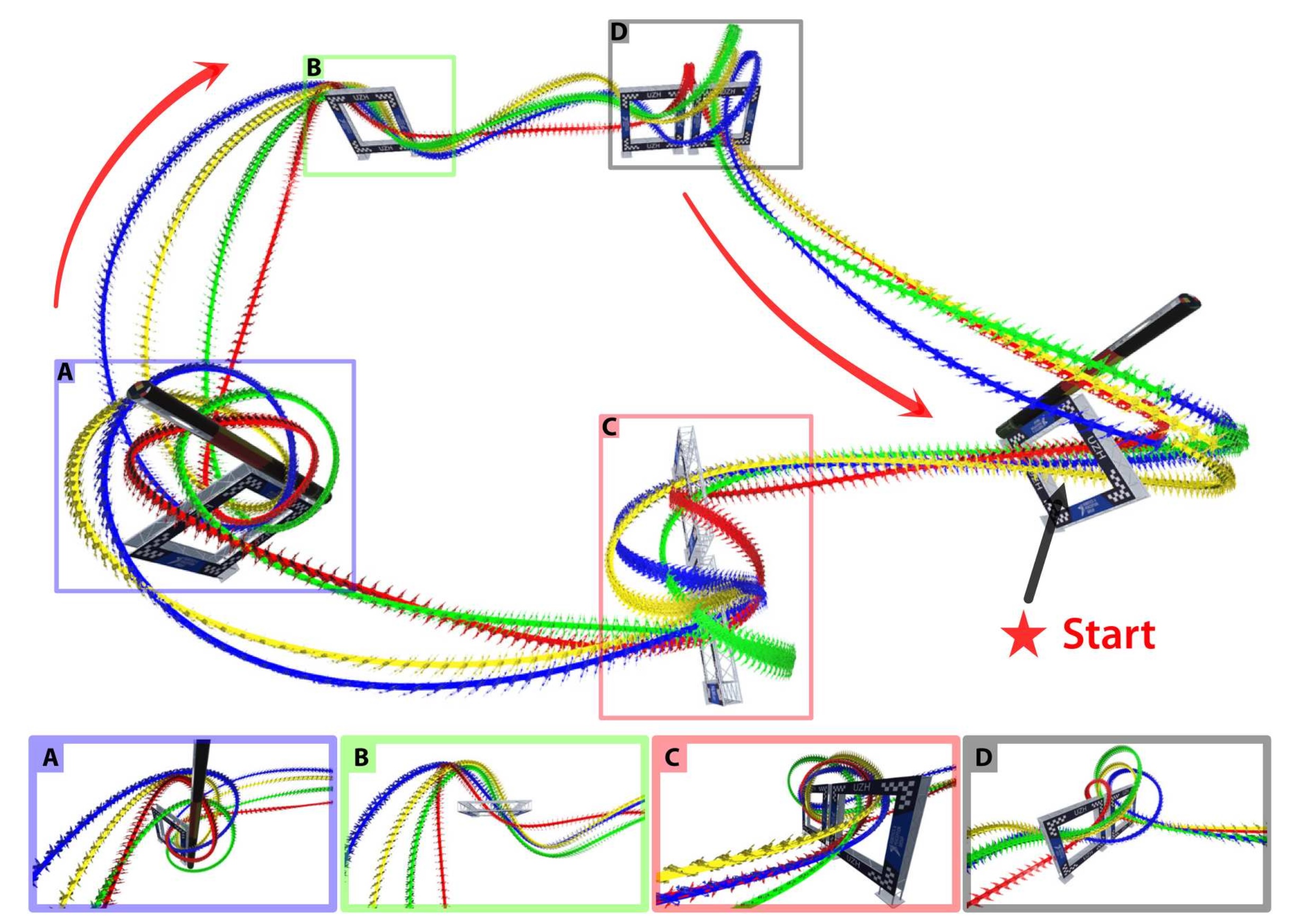
A central question in robotics is how to design a control system for an agile mobile robot. This paper studies this question systematically, focusing on a challenging setting: autonomous drone racing. We show that a neural network controller trained with reinforcement learning (RL) outperformed optimal control (OC) methods in this setting. We then investigated which fundamental factors have contributed to the success of RL or have limited OC. Our study indicates that the fundamental advantage of RL over OC is not that it optimizes its objective better but that it optimizes a better objective. OC decomposes the problem into planning and control with an explicit intermediate representation, such as a trajectory, that serves as an interface. This decomposition limits the range of behaviors that can be expressed by the controller, leading to inferior control performance when facing unmodeled effects. In contrast, RL can directly optimize a task-level objective and can leverage domain randomization to cope with model uncertainty, allowing the discovery of more robust control responses. Our findings allowed us to push an agile drone to its maximum performance, achieving a peak acceleration greater than 12 times the gravitational acceleration and a peak velocity of 108 kilometers per hour. Our policy achieved superhuman control within minutes of training on a standard workstation. This work presents a milestone in agile robotics and sheds light on the role of RL and OC in robot control.
Reaching the limit in autonomous racing: Optimal control versus reinforcement learning