Publications
Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun
International Conference on Learning Representations (ICLR), 2025
Alejandro Newell, Peiyun Hu, Lahav Lipson, Stephan Richter, Vladlen Koltun
International Conference on Learning Representations (ICLR), 2025
Ankit Goyal, Alexey Bochkovskiy, Jia Deng, and Vladlen Koltun
Advances in Neural Information Processing Systems (NeurIPS), 2022
Xingyi Zhou, Vladlen Koltun, and Philipp Krähenbühl
Computer Vision and Pattern Recognition (CVPR), 2022
Xingyi Zhou, Tianwei Yin, Vladlen Koltun, and Philipp Krähenbühl
Computer Vision and Pattern Recognition (CVPR), 2022
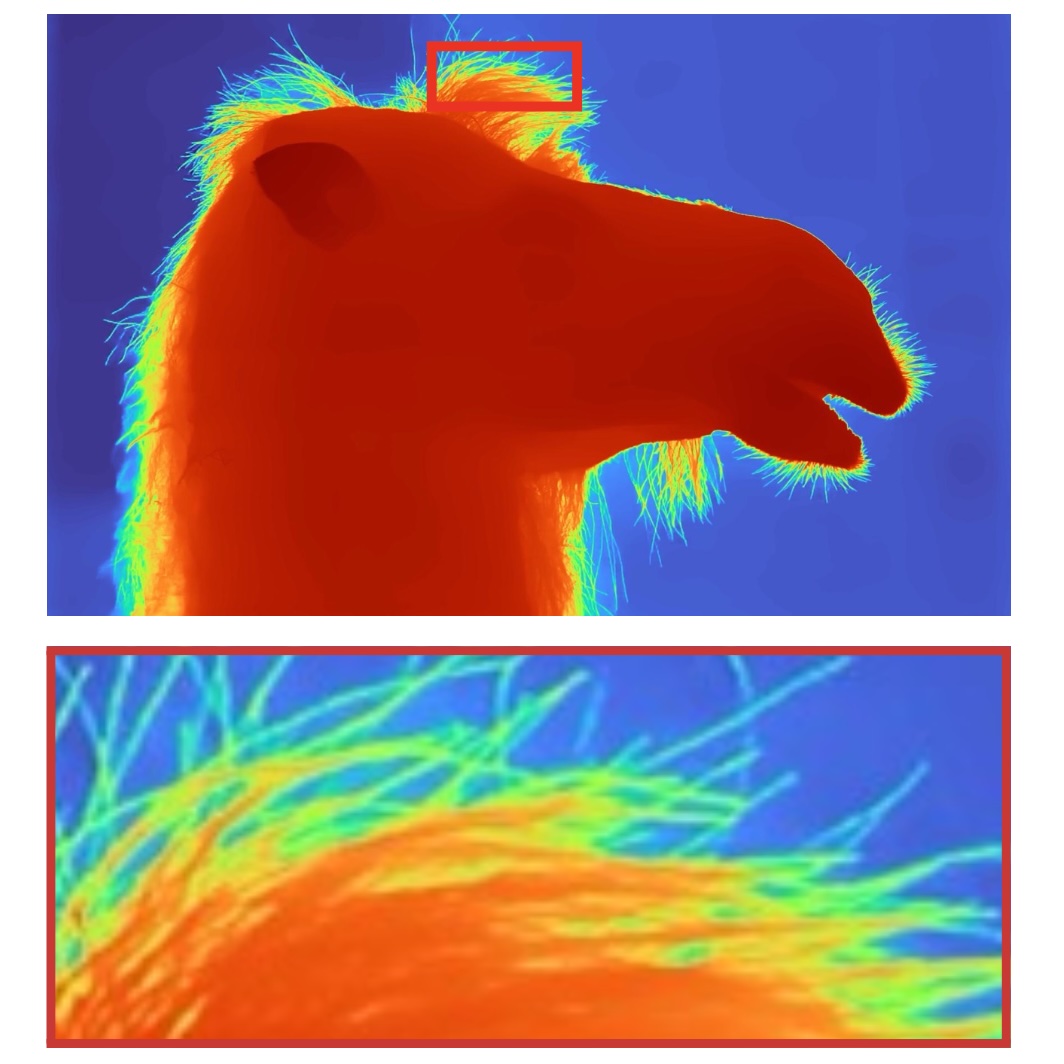
Boyi Li, Kilian Q. Weinberger, Serge Belongie, Vladlen Koltun, and René Ranftl
International Conference on Learning Representations (ICLR), 2022
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun
International Conference on Computer Vision (ICCV), 2021
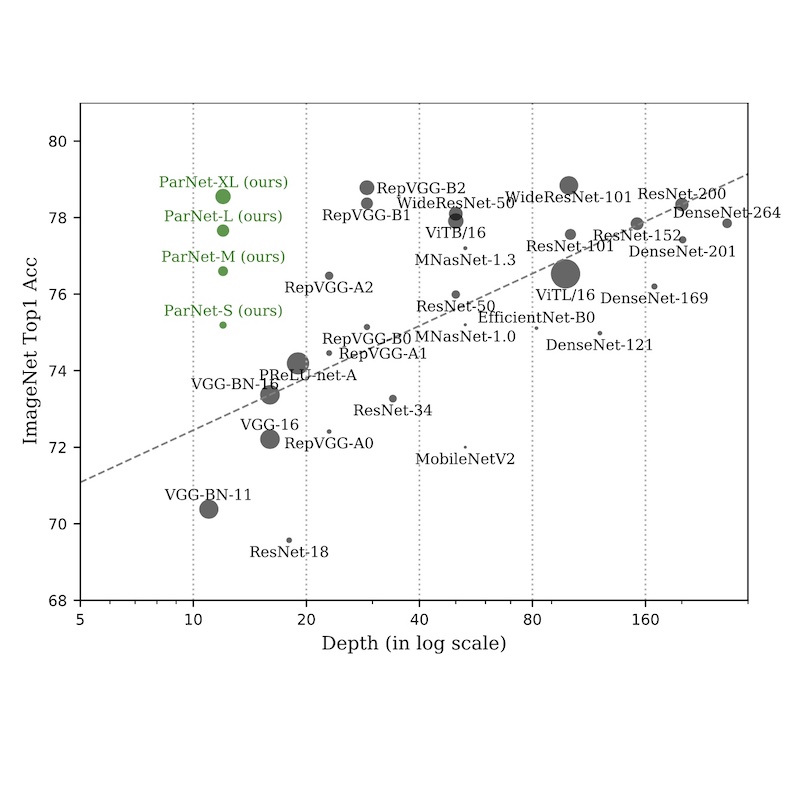
Shaojie Bai, Vladlen Koltun, and J. Zico Kolter
Advances in Neural Information Processing Systems (NeurIPS), 2020
(Selected for full oral presentation)
Xingyi Zhou, Vladlen Koltun, and Philipp Krähenbühl
European Conference on Computer Vision (ECCV), 2020
(Selected for spotlight oral presentation)
John Lambert, Zhuang Liu, Ozan Sener, James Hays, and Vladlen Koltun
Computer Vision and Pattern Recognition (CVPR), 2020
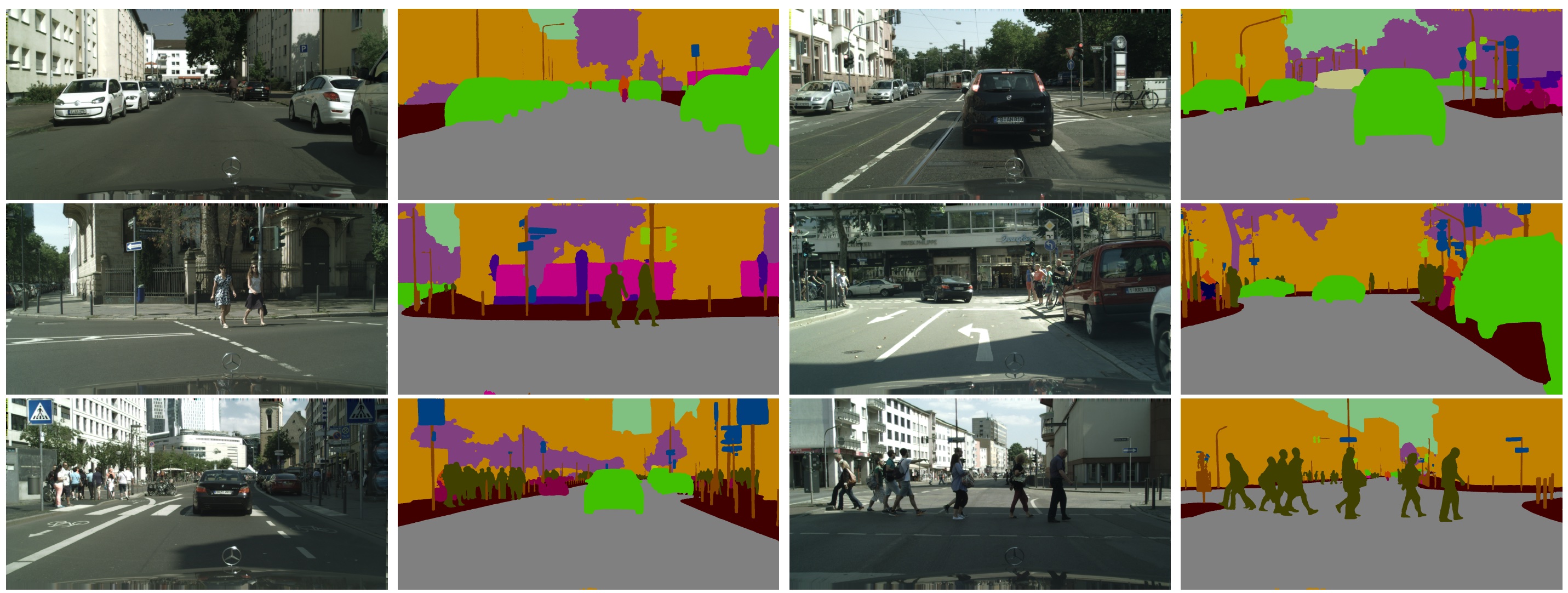
Hengshuang Zhao, Jiaya Jia, and Vladlen Koltun
Computer Vision and Pattern Recognition (CVPR), 2020
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun
IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3), 2022
Brady Zhou, Philipp Krähenbühl, and Vladlen Koltun
Science Robotics, 4(30), 2019
Stephan R. Richter, Zeeshan Hayder, and Vladlen Koltun
International Conference on Computer Vision (ICCV), 2017 (Selected for spotlight oral presentation)
Fisher Yu, Vladlen Koltun, and Thomas Funkhouser
Computer Vision and Pattern Recognition (CVPR), 2017
Stephan R. Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun
European Conference on Computer Vision (ECCV), 2016
Abhijit Kundu, Vibhav Vineet, and Vladlen Koltun
Computer Vision and Pattern Recognition (CVPR), 2016 (Selected for full oral presentation)
René Ranftl, Vibhav Vineet, Qifeng Chen, and Vladlen Koltun
Computer Vision and Pattern Recognition (CVPR), 2016
Fisher Yu and Vladlen Koltun
International Conference on Learning Representations (ICLR), 2016
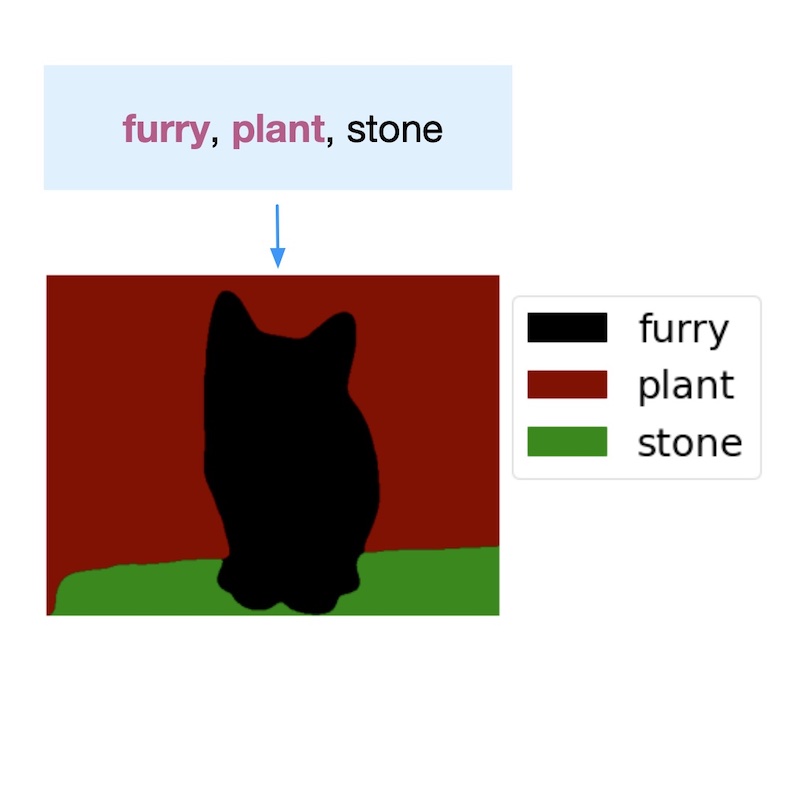
Philipp Krähenbühl and Vladlen Koltun
International Conference on Machine Learning (ICML), 2013
Philipp Krähenbühl and Vladlen Koltun
Advances in Neural Information Processing Systems, 2011 (Oustanding Student Paper Award)